Section 5.5 — Hierarchical models#
This notebook contains the code examples from Section 5.5 Hierarchical models from the No Bullshit Guide to Statistics.
See also:
https://mc-stan.org/users/documentation/case-studies/radon_cmdstanpy_plotnine.html#data-prep
https://www.pymc.io/projects/examples/en/latest/generalized_linear_models/multilevel_modeling.html
Notebook setup#
# Ensure required Python modules are installed
# %pip install --quiet numpy scipy seaborn statsmodels bambi==0.15.0 pymc==5.23.0 ministats
# Load Python modules
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Figures setup
plt.clf() # needed otherwise `sns.set_theme` doesn't work
sns.set_theme(
context="paper",
style="whitegrid",
palette="colorblind",
rc={"font.family": "serif",
"font.serif": ["Palatino", "DejaVu Serif", "serif"],
"figure.figsize": (5,3)},
)
%config InlineBackend.figure_format = "retina"
<Figure size 640x480 with 0 Axes>
# Simple float __repr__
if int(np.__version__.split(".")[0]) >= 2:
np.set_printoptions(legacy='1.25')
# Set random seed for repeatability
np.random.seed(42)
# Download datasets/ directory if necessary
from ministats import ensure_datasets
ensure_datasets()
datasets/ directory already exists.
# silence statsmodels kurtosistest warning when using n < 20
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=UserWarning)
# silence ERROR messages when showing model graphs
# cf. https://github.com/pymc-devs/pymc/issues/7901
import logging
logging.getLogger("pytensor.graph.rewriting.basic").setLevel(logging.CRITICAL)
Definitions#
Hierarchical (multilevel) models#
Model formula#
A Bayesian hierarchical model is described by the following equations:
\(\def\calN{\mathcal{N}} \def\Tdist{\mathcal{T}} \def\Expon{\mathrm{Expon}}\)
Radon dataset#
https://bambinos.github.io/bambi/notebooks/radon_example.html
Description: Contains measurements of radon levels in homes across various counties.
Source: Featured in Andrew Gelman and Jennifer Hill’s book Data Analysis Using Regression and Multilevel/Hierarchical Models.
Application: Demonstrates partial pooling and varying intercepts/slopes in hierarchical modeling.
Loading the data#
radon = pd.read_csv("datasets/radon.csv")
radon.shape
(919, 6)
radon.head()
| idnum | state | county | floor | log_radon | log_uranium | |
|---|---|---|---|---|---|---|
| 0 | 5081 | MN | AITKIN | ground | 0.788457 | -0.689048 |
| 1 | 5082 | MN | AITKIN | basement | 0.788457 | -0.689048 |
| 2 | 5083 | MN | AITKIN | basement | 1.064711 | -0.689048 |
| 3 | 5084 | MN | AITKIN | basement | 0.000000 | -0.689048 |
| 4 | 5085 | MN | ANOKA | basement | 1.131402 | -0.847313 |
Descriptive statistics#
radon["log_radon"].describe()
count 919.000000
mean 1.224623
std 0.853327
min -2.302585
25% 0.641854
50% 1.280934
75% 1.791759
max 3.875359
Name: log_radon, dtype: float64
len(radon["county"].unique())
85
radon["floor"].value_counts()
floor
basement 766
ground 153
Name: count, dtype: int64
from ministats.book.figures import plot_counties
sel_counties = [
"LAC QUI PARLE", "AITKIN", "KOOCHICHING", "DOUGLAS",
"HENNEPIN", "STEARNS", "RAMSEY", "ST LOUIS",
]
plot_counties(radon, counties=sel_counties);
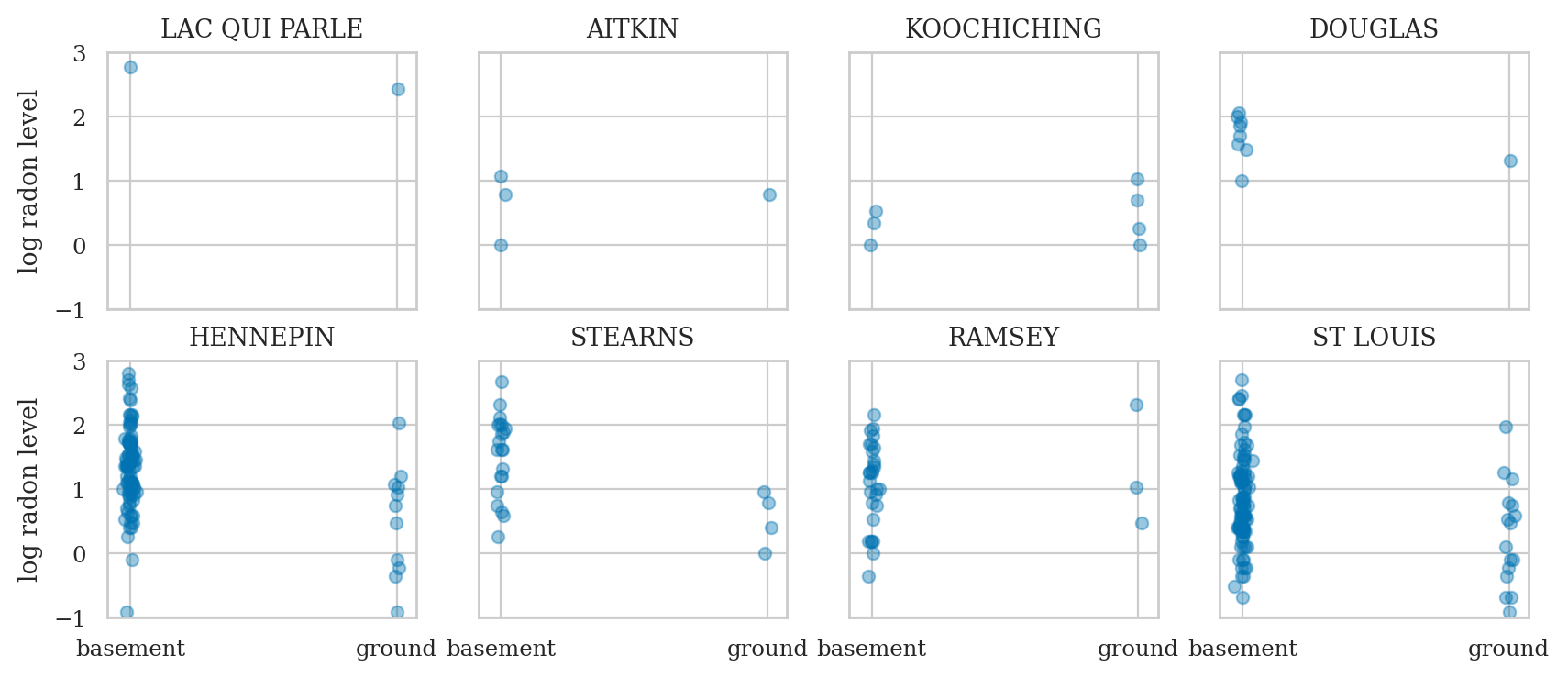
Example 1: complete pooling model#
= common linear regression model for all counties
Bayesian model#
We can pool all the data and estimate one big regression to asses the influence of the floor variable on radon levels across all counties.
The variable \(f\) corresponds to the column floor in the radon data frame,
which will be internally coded as binary
with \(0\) representing basement,
and \(1\) representing ground floor.
By ignoring the county feature, we do not differenciate on counties.
Bambi model#
import bambi as bmb
priors1 = {
"Intercept": bmb.Prior("Normal", mu=1, sigma=2),
"floor": bmb.Prior("Normal", mu=0, sigma=5),
"sigma": bmb.Prior("HalfStudentT", nu=4, sigma=1),
}
mod1 = bmb.Model(formula="log_radon ~ 1 + floor",
family="gaussian",
link="identity",
priors=priors1,
data=radon)
mod1
Formula: log_radon ~ 1 + floor
Family: gaussian
Link: mu = identity
Observations: 919
Priors:
target = mu
Common-level effects
Intercept ~ Normal(mu: 1.0, sigma: 2.0)
floor ~ Normal(mu: 0.0, sigma: 5.0)
Auxiliary parameters
sigma ~ HalfStudentT(nu: 4.0, sigma: 1.0)
mod1.build()
mod1.graph()

Model fitting and analysis#
idata1 = mod1.fit(random_seed=42)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [sigma, Intercept, floor]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
We recommend running at least 4 chains for robust computation of convergence diagnostics
import arviz as az
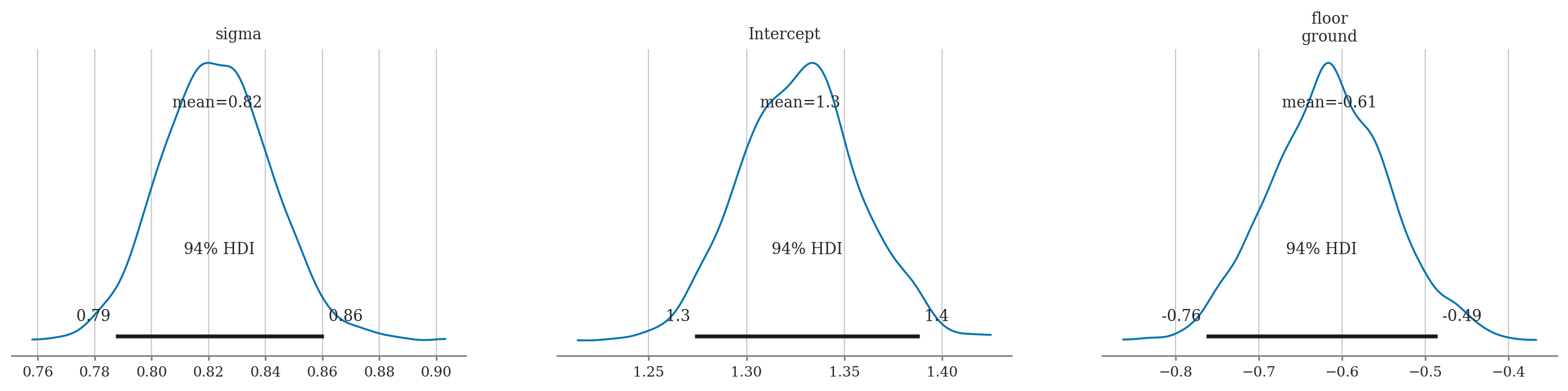
az.summary(idata1, kind="stats")
| mean | sd | hdi_3% | hdi_97% | |
|---|---|---|---|---|
| sigma | 0.823 | 0.020 | 0.787 | 0.860 |
| Intercept | 1.327 | 0.031 | 1.274 | 1.389 |
| floor[ground] | -0.615 | 0.073 | -0.763 | -0.485 |
az.plot_posterior(idata1);
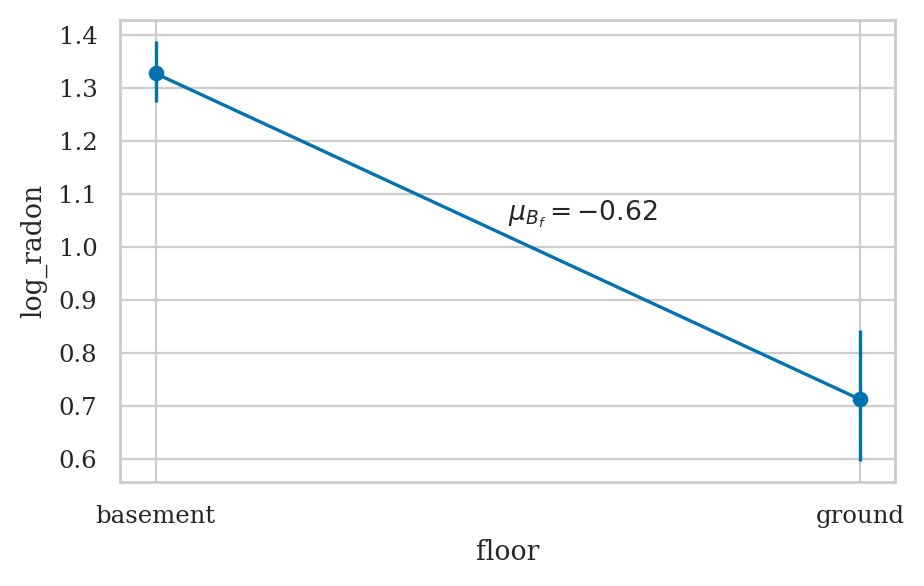
fig, axs = bmb.interpret.plot_predictions(mod1, idata1, conditional="floor")
means1 = az.summary(idata1, kind="stats")["mean"]
y0 = means1["Intercept"]
y1 = means1["Intercept"] + means1["floor[ground]"]
sns.lineplot(x=[0,1], y=[y0,y1], ax=axs[0]);
midpoint = [0.5, (y0+y1)/2 + 0.03]
slope = means1["floor[ground]"].round(2)
axs[0].annotate("$\\mu_{B_{f}}=%.2f$" % slope, midpoint);
Default computed for conditional variable: floor
Conclusion#
not using group membership, so we have lots of bias
Example 2: no pooling model#
= separate intercept for each county
Bayesian model#
If we treat different counties as independent, so each one gets an intercept term:
Bambi model#
priors2 = {
"county": bmb.Prior("Normal", mu=1, sigma=2),
"floor": bmb.Prior("Normal", mu=0, sigma=5),
"sigma": bmb.Prior("HalfStudentT", nu=4, sigma=1),
}
mod2 = bmb.Model("log_radon ~ 0 + county + floor",
family="gaussian",
link="identity",
priors=priors2,
data=radon)
mod2
Formula: log_radon ~ 0 + county + floor
Family: gaussian
Link: mu = identity
Observations: 919
Priors:
target = mu
Common-level effects
county ~ Normal(mu: 1.0, sigma: 2.0)
floor ~ Normal(mu: 0.0, sigma: 5.0)
Auxiliary parameters
sigma ~ HalfStudentT(nu: 4.0, sigma: 1.0)
mod2.build()
mod2.graph()

Model fitting and analysis#
idata2 = mod2.fit(random_seed=42)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [sigma, county, floor]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 3 seconds.
We recommend running at least 4 chains for robust computation of convergence diagnostics
idata2sel = idata2.sel(county_dim=sel_counties)
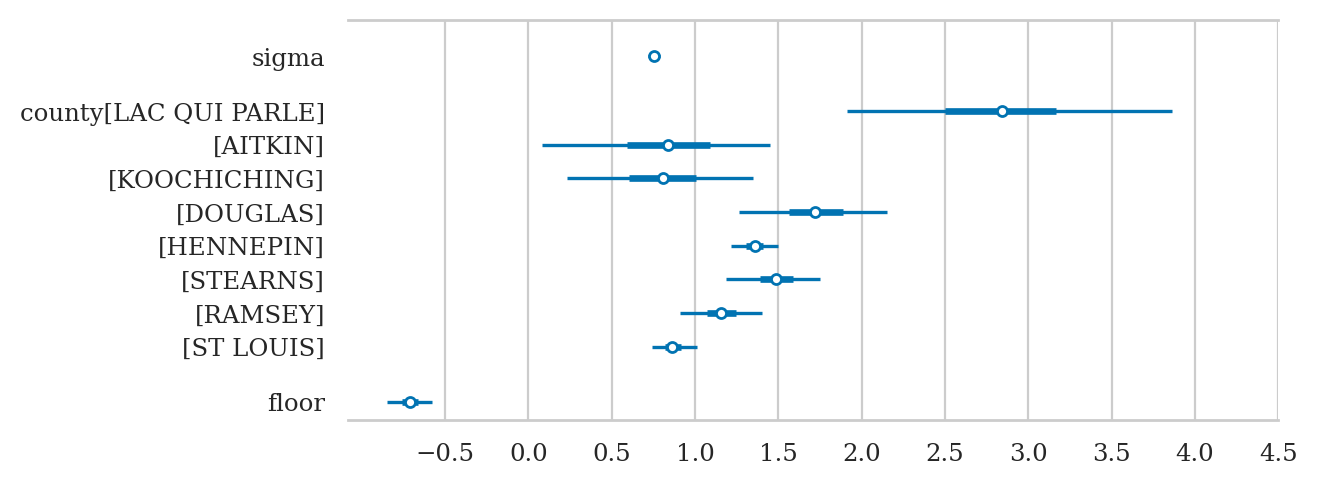
az.summary(idata2sel, kind="stats")
| mean | sd | hdi_3% | hdi_97% | |
|---|---|---|---|---|
| sigma | 0.756 | 0.019 | 0.719 | 0.790 |
| county[LAC QUI PARLE] | 2.836 | 0.505 | 1.914 | 3.862 |
| county[AITKIN] | 0.836 | 0.364 | 0.082 | 1.450 |
| county[KOOCHICHING] | 0.809 | 0.298 | 0.229 | 1.345 |
| county[DOUGLAS] | 1.722 | 0.238 | 1.262 | 2.151 |
| county[HENNEPIN] | 1.358 | 0.075 | 1.216 | 1.495 |
| county[STEARNS] | 1.487 | 0.151 | 1.187 | 1.748 |
| county[RAMSEY] | 1.158 | 0.132 | 0.909 | 1.400 |
| county[ST LOUIS] | 0.865 | 0.073 | 0.741 | 1.009 |
| floor[ground] | -0.708 | 0.071 | -0.846 | -0.579 |
axs = az.plot_forest(idata2sel, combined=True, figsize=(6,2.6))
axs[0].set_xticks(np.arange(-0.5,4.6,0.5))
axs[0].set_title(None);
plot_counties(radon, idata_cp=idata1, idata_np=idata2);
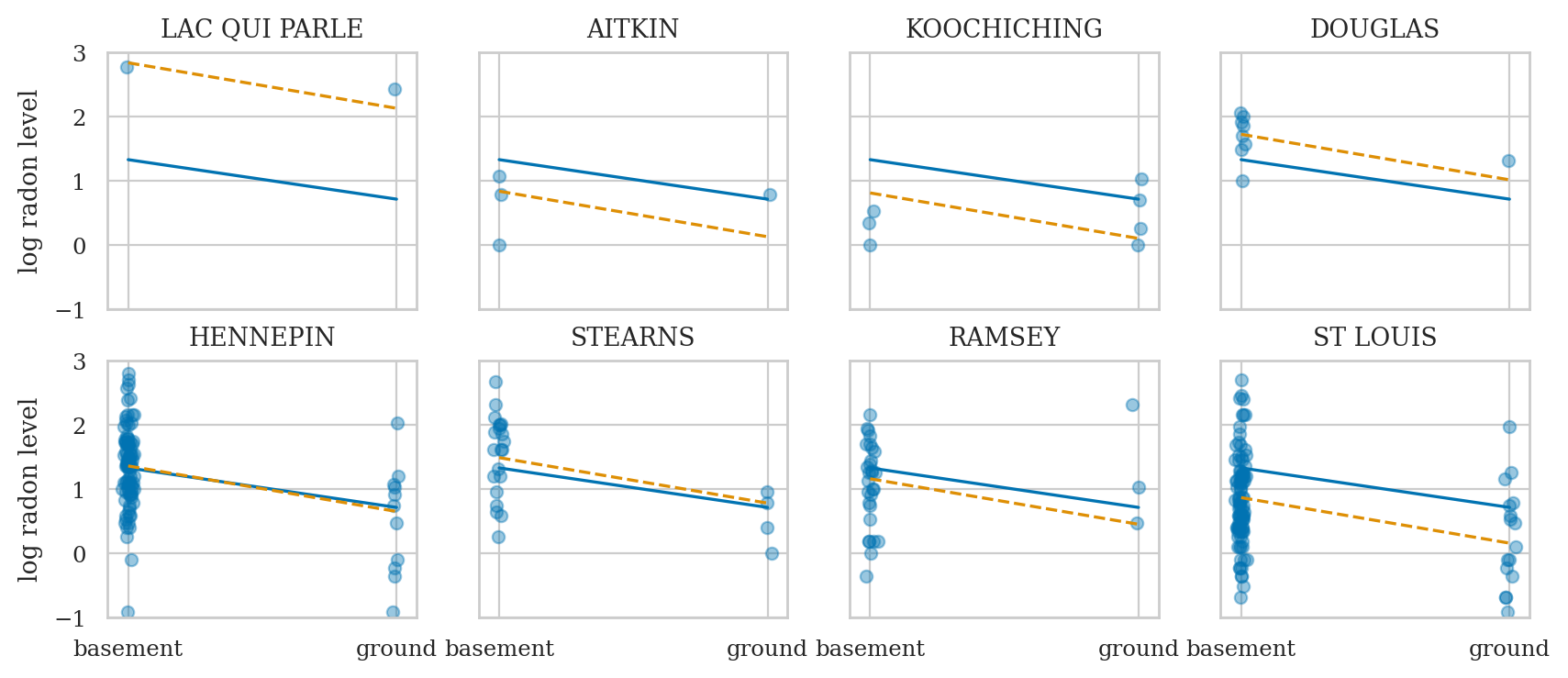
# fig, axs = bmb.interpret.plot_predictions(mod2, idata2, ["floor", "county"]);
# axs[0].get_legend().remove()
# post2 = idata2["posterior"]
# unpooled_means = post2.mean(dim=("chain", "draw"))
# unpooled_hdi = az.hdi(idata2)
# unpooled_means_iter = unpooled_means.sortby("county")
# unpooled_hdi_iter = unpooled_hdi.sortby(unpooled_means_iter.county)
# _, ax = plt.subplots(figsize=(12, 5))
# unpooled_means_iter.plot.scatter(x="county_dim", y="county", ax=ax, alpha=0.9)
# ax.vlines(
# np.arange(len(radon["county"].unique())),
# unpooled_hdi_iter.county.sel(hdi="lower"),
# unpooled_hdi_iter.county.sel(hdi="higher"),
# color="orange",
# alpha=0.6,
# )
# ax.set(ylabel="Radon estimate", ylim=(-2, 4.5))
# ax.tick_params(rotation=90);
Conclusion#
treating each group independently, so we have lots of variance
# TODO:
# calculate the std.dev. of the county-specific slopes -- this is like \Sigma_J but w/o a prior.
Example 3: hierarchical model#
= partial pooling model = varying intercepts model
Bayesian hierarchical model#
The partial pooling formula estimates per-county intercepts which drawn
from the same distribution which is estimated jointly with the rest of
the model parameters. The 1 is the intercept co-efficient. The
estimates across counties will all have the same slope.
log_radon ~ 1 + (1|county_id) + floor
There is a middle ground to both of these extremes. Specifically, we may assume that the intercepts are different for each county as in the unpooled case, but they are drawn from the same distribution. The different counties are effectively sharing information through the common prior.
NOTE: some counties have very few sample; the hierarchical model will provide “shrinkage” for these groups, and use global information learned from all counties
radon["log_radon"].describe()
count 919.000000
mean 1.224623
std 0.853327
min -2.302585
25% 0.641854
50% 1.280934
75% 1.791759
max 3.875359
Name: log_radon, dtype: float64
radon.groupby("floor")["log_radon"].describe()
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| floor | ||||||||
| basement | 766.0 | 1.326744 | 0.782709 | -2.302585 | 0.788457 | 1.360977 | 1.883253 | 3.875359 |
| ground | 153.0 | 0.713349 | 0.999376 | -2.302585 | 0.095310 | 0.741937 | 1.308333 | 3.234749 |
Bambi model#
priors3 = {
"Intercept": bmb.Prior("Normal", mu=1, sigma=2),
"floor": bmb.Prior("Normal", mu=0, sigma=5),
"1|county": bmb.Prior("Normal", mu=0, sigma=bmb.Prior("Exponential", lam=1)),
"sigma": bmb.Prior("HalfStudentT", nu=4, sigma=1),
}
formula3 = "log_radon ~ 1 + (1|county) + floor"
mod3 = bmb.Model(formula=formula3,
family="gaussian",
link="identity",
priors=priors3,
data=radon,
noncentered=False)
mod3
Formula: log_radon ~ 1 + (1|county) + floor
Family: gaussian
Link: mu = identity
Observations: 919
Priors:
target = mu
Common-level effects
Intercept ~ Normal(mu: 1.0, sigma: 2.0)
floor ~ Normal(mu: 0.0, sigma: 5.0)
Group-level effects
1|county ~ Normal(mu: 0.0, sigma: Exponential(lam: 1.0))
Auxiliary parameters
sigma ~ HalfStudentT(nu: 4.0, sigma: 1.0)
mod3.build()
mod3.graph()

Model fitting and analysis#
idata3 = mod3.fit(random_seed=42)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [sigma, Intercept, floor, 1|county_sigma, 1|county]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 3 seconds.
We recommend running at least 4 chains for robust computation of convergence diagnostics
The group level parameters
idata3sel = idata3.sel(county__factor_dim=sel_counties)
az.summary(idata3sel, kind="stats")
| mean | sd | hdi_3% | hdi_97% | |
|---|---|---|---|---|
| sigma | 0.757 | 0.018 | 0.725 | 0.791 |
| Intercept | 1.460 | 0.051 | 1.361 | 1.551 |
| floor[ground] | -0.693 | 0.073 | -0.824 | -0.549 |
| 1|county_sigma | 0.334 | 0.046 | 0.258 | 0.425 |
| 1|county[LAC QUI PARLE] | 0.412 | 0.304 | -0.173 | 0.969 |
| 1|county[AITKIN] | -0.267 | 0.263 | -0.770 | 0.189 |
| 1|county[KOOCHICHING] | -0.362 | 0.225 | -0.771 | 0.081 |
| 1|county[DOUGLAS] | 0.172 | 0.200 | -0.216 | 0.532 |
| 1|county[HENNEPIN] | -0.097 | 0.086 | -0.262 | 0.064 |
| 1|county[STEARNS] | 0.027 | 0.138 | -0.229 | 0.292 |
| 1|county[RAMSEY] | -0.257 | 0.134 | -0.500 | -0.005 |
| 1|county[ST LOUIS] | -0.567 | 0.085 | -0.735 | -0.413 |
The intercept offsets for each county are:
# sum( idata3["posterior"]["1|county"].stack(sample=("chain","draw")).values.mean(axis=1) )
# az.plot_forest(idata3, combined=True, figsize=(7,2),
# var_names=["Intercept", "floor", "1|county_sigma", "sigma"]);
axs = az.plot_forest(idata3sel,
var_names=["Intercept", "1|county", "floor", "1|county_sigma", "sigma"],
combined=True, figsize=(6,3))
axs[0].set_xticks(np.arange(-0.8,1.6,0.2))
axs[0].set_title(None);
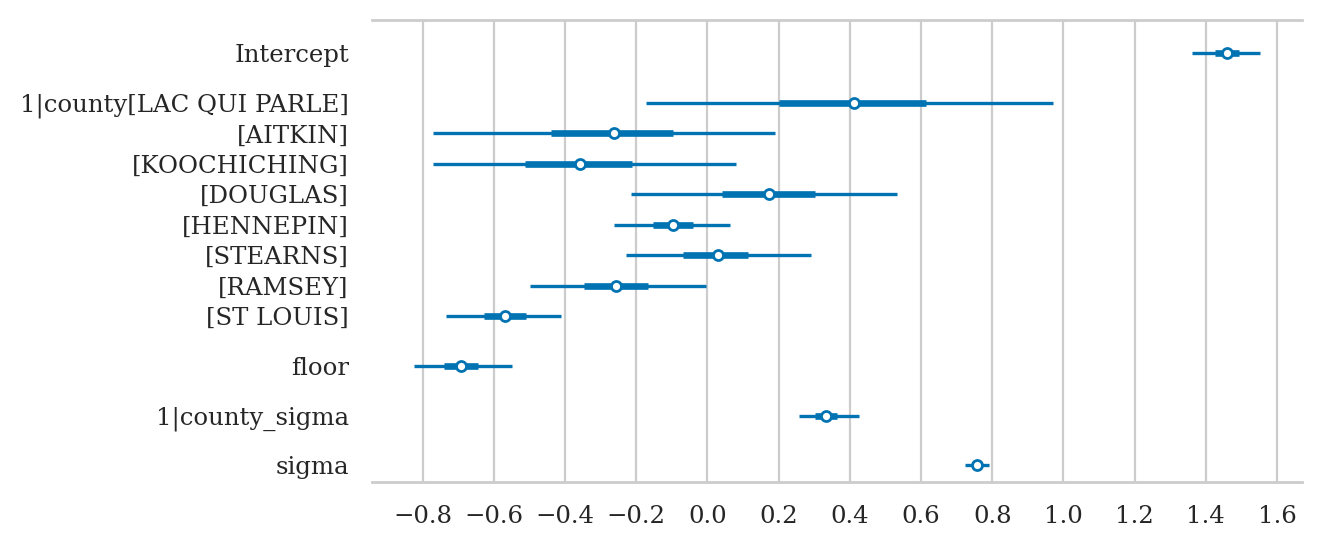
# az.plot_forest(idata3, var_names=["1|county"], combined=True);
Compare models#
Compare complete pooling, no pooling, and partial pooling models
plot_counties(radon, idata_cp=idata1, idata_np=idata2, idata_pp=idata3);
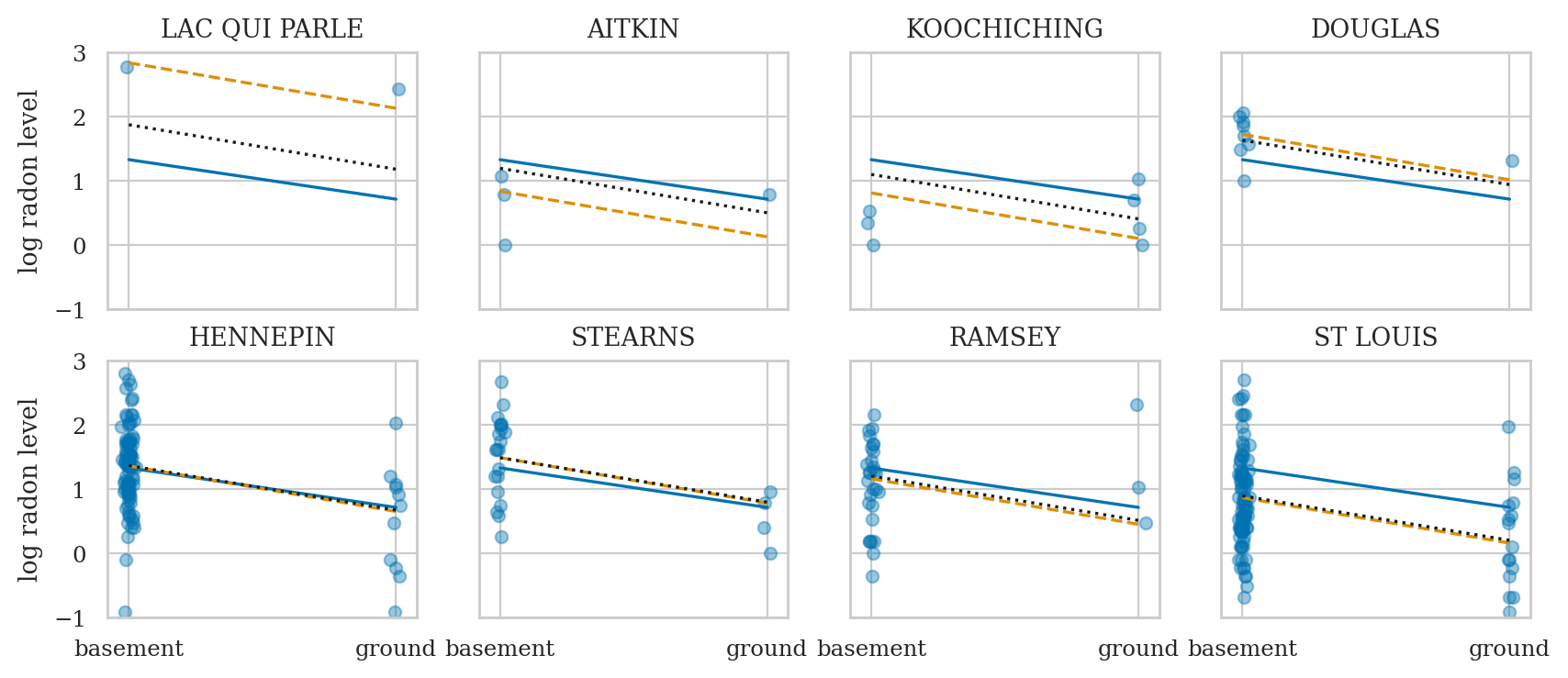
# # Forest plot comparing `mod2` and `mod3` estimates
# # (to illustrate reduced uncertainty in estimates + shrinkage)
# post3 = idata3sel["posterior"]
# post3["county"] = post3["Intercept"] + post3["1|county"]
# axs = az.plot_forest([idata2sel, idata3sel], model_names=["mod2", "mod3"],
# var_names=["county", "floor", "1|county_sigma", "sigma"], combined=True, figsize=(6,3))
# ax = axs[0]
# rbar = radon["log_radon"].mean()
# ax.axvline(rbar, ls="--");
Conclusions#
Explanations#
Prior selection for hierarchical models#
?
Varying intercepts and slopes model#
= Group-specific slopes We can also make beta_x group-specific
The varying-slope, varying intercept model adds floor to the
group-level co-efficients. Now estimates across counties will all have
varying slope.
log_radon ~ 1 + floor + (1 + floor | county)
#######################################################
formula4 = "log_radon ~ 1 + (1|county) + floor + (floor|county)"
SigmaB0j = bmb.Prior("Exponential", lam=1)
SigmaBfj = bmb.Prior("Exponential", lam=1)
priors4 = {
"Intercept": bmb.Prior("Normal", mu=1, sigma=2),
"1|county": bmb.Prior("Normal", mu=0, sigma=SigmaB0j),
"floor": bmb.Prior("Normal", mu=-1, sigma=2),
"floor|county": bmb.Prior("Normal", mu=0, sigma=SigmaBfj),
"sigma": bmb.Prior("HalfStudentT", nu=4, sigma=1),
}
mod4 = bmb.Model(formula=formula4,
family="gaussian",
link="identity",
priors=priors4,
data=radon,
noncentered=False)
mod4
Formula: log_radon ~ 1 + (1|county) + floor + (floor|county)
Family: gaussian
Link: mu = identity
Observations: 919
Priors:
target = mu
Common-level effects
Intercept ~ Normal(mu: 1.0, sigma: 2.0)
floor ~ Normal(mu: -1.0, sigma: 2.0)
Group-level effects
1|county ~ Normal(mu: 0.0, sigma: Exponential(lam: 1.0))
floor|county ~ Normal(mu: 0.0, sigma: Exponential(lam: 1.0))
Auxiliary parameters
sigma ~ HalfStudentT(nu: 4.0, sigma: 1.0)
mod4.build()
mod4.graph()

idata4 = mod4.fit(draws=2000, tune=3000, random_seed=42, target_accept=0.9)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [sigma, Intercept, floor, 1|county_sigma, 1|county, floor|county_sigma, floor|county]
Sampling 2 chains for 3_000 tune and 2_000 draw iterations (6_000 + 4_000 draws total) took 14 seconds.
We recommend running at least 4 chains for robust computation of convergence diagnostics
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
# az.autocorr(idata4["posterior"]["sigma"].values.flatten())[0:10]
idata4sel = idata4.sel(county__factor_dim=sel_counties)
az.summary(idata4sel, kind="stats")
| mean | sd | hdi_3% | hdi_97% | |
|---|---|---|---|---|
| sigma | 0.749 | 0.019 | 0.716 | 0.786 |
| Intercept | 1.458 | 0.055 | 1.358 | 1.562 |
| floor[ground] | -0.675 | 0.088 | -0.840 | -0.510 |
| 1|county_sigma | 0.335 | 0.046 | 0.247 | 0.416 |
| 1|county[LAC QUI PARLE] | 0.392 | 0.295 | -0.196 | 0.917 |
| 1|county[AITKIN] | -0.283 | 0.255 | -0.747 | 0.204 |
| 1|county[KOOCHICHING] | -0.400 | 0.245 | -0.868 | 0.061 |
| 1|county[DOUGLAS] | 0.169 | 0.200 | -0.202 | 0.548 |
| 1|county[HENNEPIN] | -0.088 | 0.090 | -0.255 | 0.084 |
| 1|county[STEARNS] | 0.033 | 0.146 | -0.239 | 0.306 |
| 1|county[RAMSEY] | -0.278 | 0.132 | -0.529 | -0.033 |
| 1|county[ST LOUIS] | -0.578 | 0.090 | -0.743 | -0.410 |
| floor|county_sigma[ground] | 0.296 | 0.115 | 0.060 | 0.489 |
| floor|county[ground, LAC QUI PARLE] | 0.173 | 0.308 | -0.350 | 0.812 |
| floor|county[ground, AITKIN] | 0.045 | 0.288 | -0.529 | 0.585 |
| floor|county[ground, KOOCHICHING] | 0.037 | 0.257 | -0.464 | 0.517 |
| floor|county[ground, DOUGLAS] | 0.055 | 0.288 | -0.477 | 0.618 |
| floor|county[ground, HENNEPIN] | -0.098 | 0.191 | -0.468 | 0.255 |
| floor|county[ground, STEARNS] | -0.101 | 0.239 | -0.585 | 0.322 |
| floor|county[ground, RAMSEY] | 0.240 | 0.277 | -0.244 | 0.778 |
| floor|county[ground, ST LOUIS] | 0.048 | 0.170 | -0.275 | 0.365 |
az.summary(idata4, var_names="sigma", kind="stats")
| mean | sd | hdi_3% | hdi_97% | |
|---|---|---|---|---|
| sigma | 0.749 | 0.019 | 0.716 | 0.786 |
The estimated mean standard deviation is the lowest of all the models we considered so far.
plot_counties(radon, idata_cp=idata1, idata_np=idata2, idata_pp=idata3, idata_pp2=idata4);
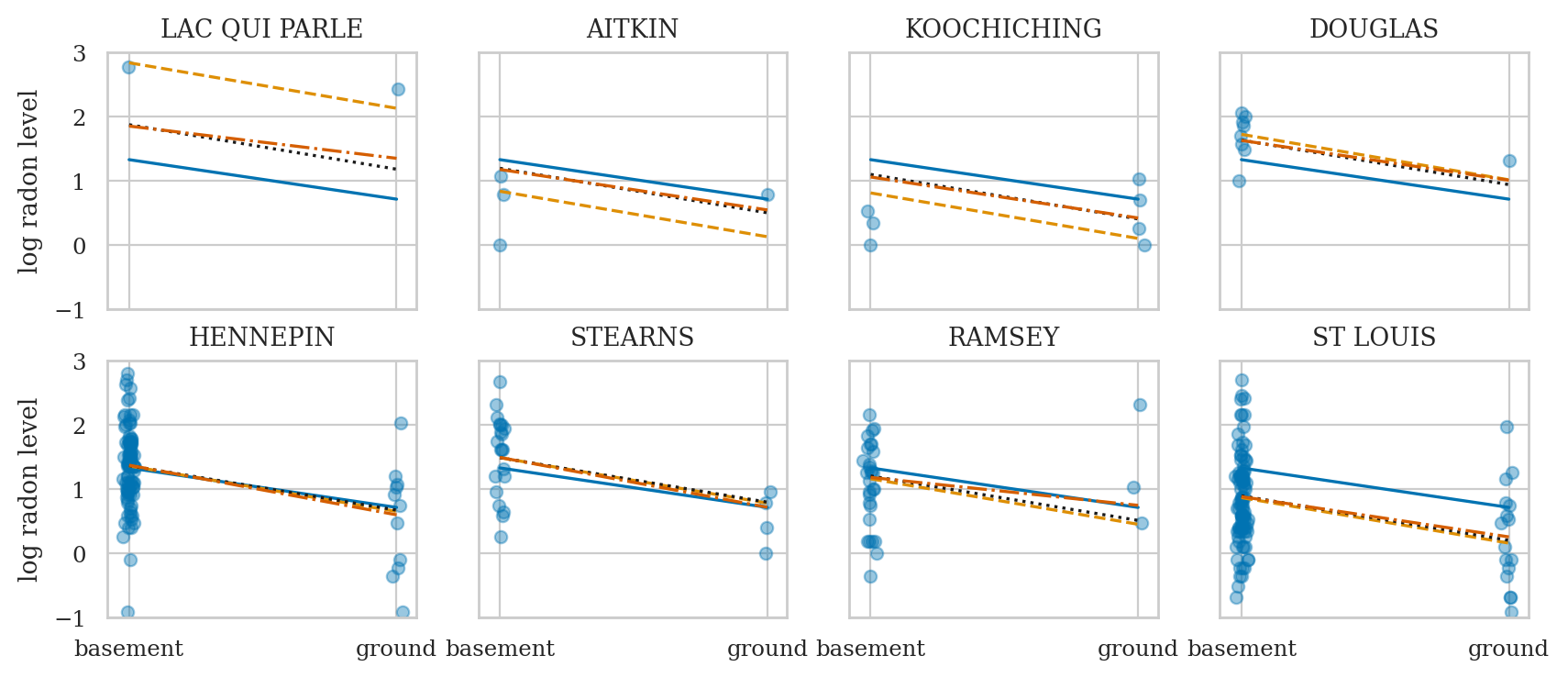
idata4sel = idata4.sel(county__factor_dim=sel_counties)
var_names = ["Intercept",
"1|county",
"floor",
"floor|county",
"1|county_sigma",
"floor|county_sigma",
"sigma"]
axs = az.plot_forest(idata4sel, combined=True, var_names=var_names, figsize=(6,4))
axs[0].set_xticks(np.arange(-1.6,1.6,0.2))
axs[0].set_title(None);
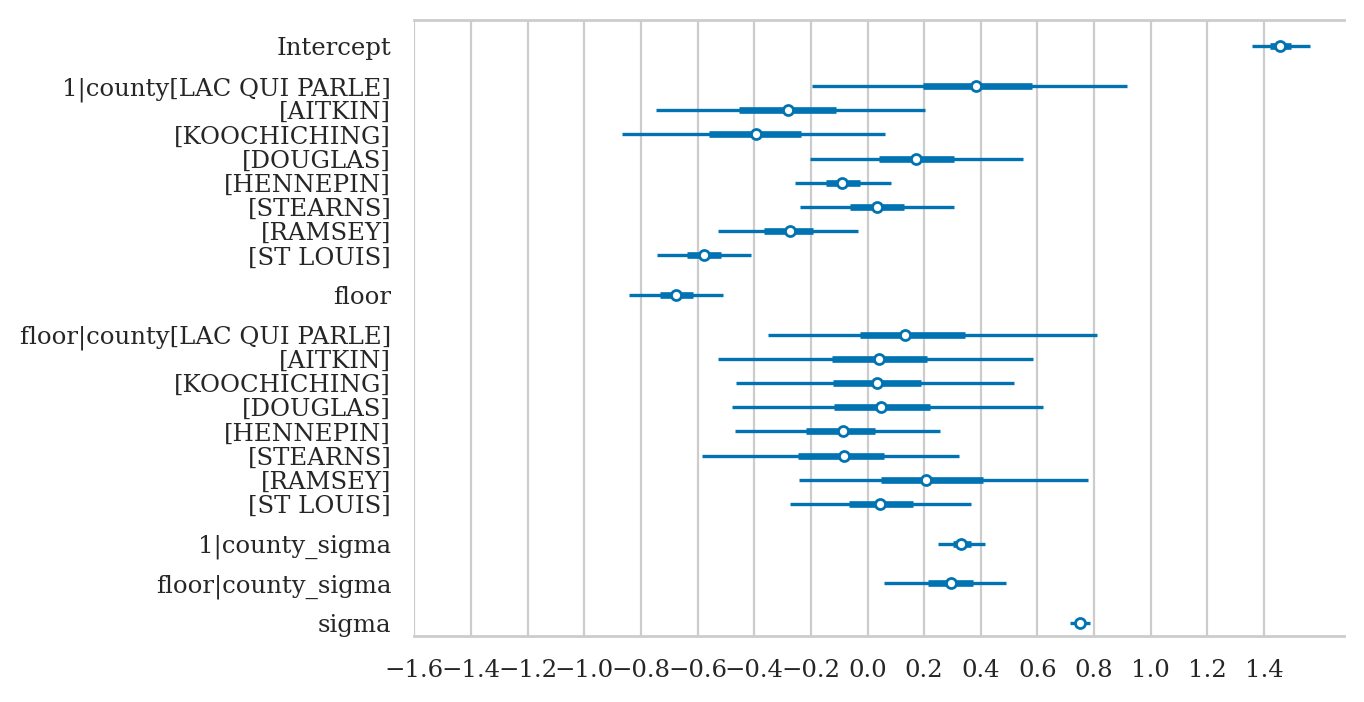
Comparing models#
from ministats.utils import loglevel
with loglevel("ERROR", module="pymc"):
idata1ll = mod1.fit(idata_kwargs={"log_likelihood": True}, random_seed=42, progressbar=False)
idata2ll = mod2.fit(idata_kwargs={"log_likelihood": True}, random_seed=42, progressbar=False)
idata3ll = mod3.fit(idata_kwargs={"log_likelihood": True}, random_seed=42, progressbar=False)
idata4ll = mod4.fit(idata_kwargs={"log_likelihood": True}, random_seed=42, progressbar=False,
draws=2000, tune=3000, target_accept=0.9)
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
Compare models based on their expected log pointwise predictive density (ELPD).
The ELPD is estimated either by Pareto smoothed importance sampling leave-one-out cross-validation (LOO) or using the widely applicable information criterion (WAIC). We recommend loo. Read more theory here - in a paper by some of the leading authorities on model comparison dx.doi.org/10.1111/1467-9868.00353
radon_models = {
"mod1 (complete pooling)": idata1ll,
"mod2 (no pooling)": idata2ll,
"mod3 (varying intercepts)": idata3ll,
"mod4 (varying int. and slopes)": idata4ll,
}
compare_results = az.compare(radon_models)
compare_results
| rank | elpd_loo | p_loo | elpd_diff | weight | se | dse | warning | scale | |
|---|---|---|---|---|---|---|---|---|---|
| mod3 (varying intercepts) | 0 | -1073.759922 | 49.025365 | 0.000000 | 5.447032e-01 | 28.088175 | 0.000000 | False | log |
| mod4 (varying int. and slopes) | 1 | -1075.753204 | 66.979000 | 1.993282 | 3.769495e-01 | 29.012613 | 2.642580 | True | log |
| mod2 (no pooling) | 2 | -1095.809462 | 83.332253 | 22.049540 | 2.591243e-17 | 28.194215 | 6.112637 | True | log |
| mod1 (complete pooling) | 3 | -1126.982196 | 3.833032 | 53.222274 | 7.834736e-02 | 25.565695 | 10.572899 | False | log |
az.plot_compare(compare_results);
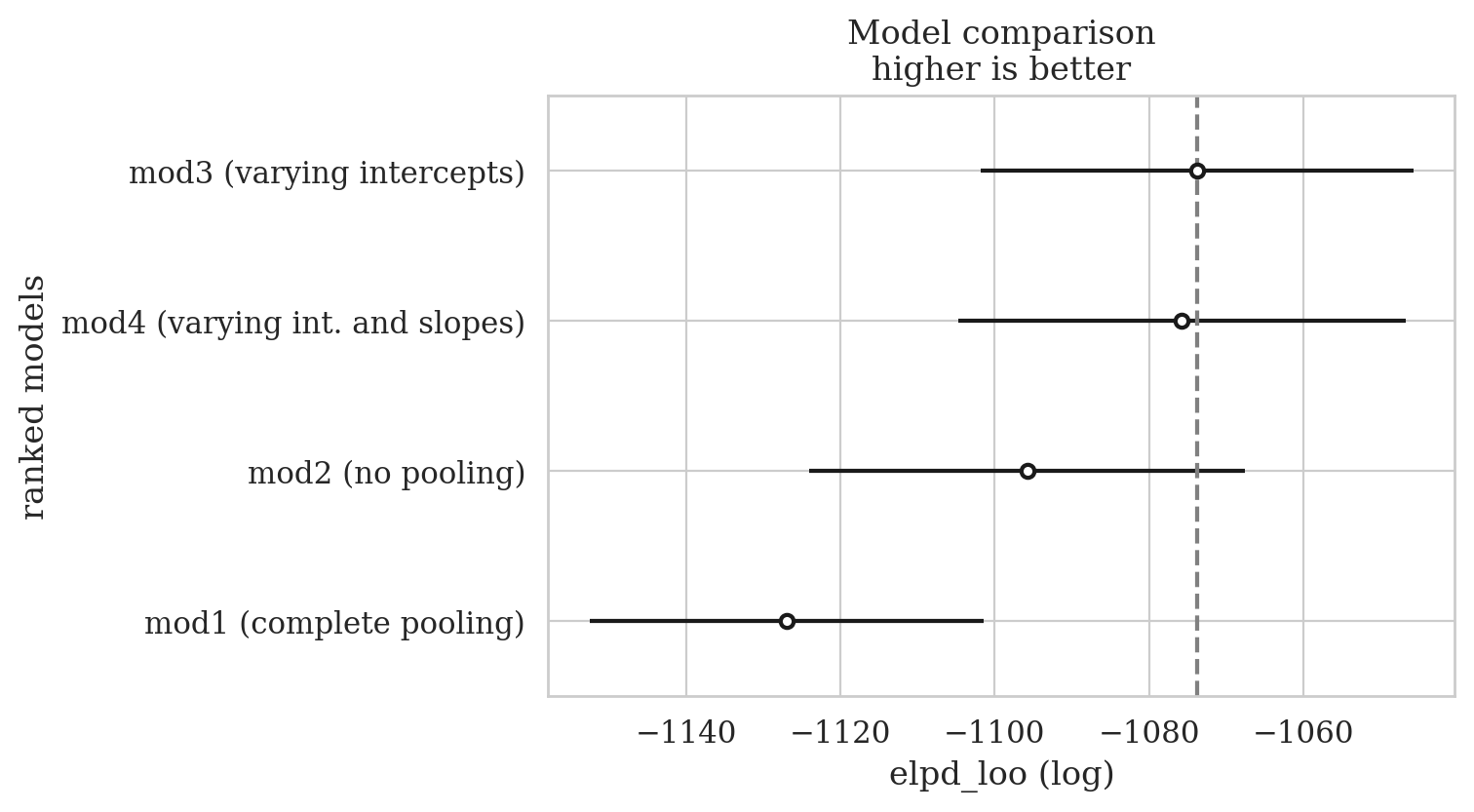
ELPD and elpd_loo#
The ELPD is the theoretical expected log pointwise predictive density for a new dataset (Eq 1 in VGG2017), which can be estimated, e.g., using cross-validation. elpd_loo is the Bayesian LOO estimate of the expected log pointwise predictive density (Eq 4 in VGG2017) and is a sum of N individual pointwise log predictive densities. Probability densities can be smaller or larger than 1, and thus log predictive densities can be negative or positive. For simplicity the ELPD acronym is used also for expected log pointwise predictive probabilities for discrete models. Probabilities are always equal or less than 1, and thus log predictive probabilities are 0 or negative.
Frequentist multilevel models#
We can use statsmodels to fit multilevel models too.
Random intercepts model using statsmodels#
import statsmodels.formula.api as smf
sm3 = smf.mixedlm("log_radon ~ 1 + floor", # Fixed effects (no intercept and floor as a fixed effect)
groups="county", # Grouping variable for random effects
re_formula="1", # Random effects = intercept
data=radon)
res3 = sm3.fit()
res3.summary().tables[1]
| Coef. | Std.Err. | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 1.462 | 0.052 | 28.164 | 0.000 | 1.360 | 1.563 |
| floor[T.ground] | -0.693 | 0.071 | -9.818 | 0.000 | -0.831 | -0.555 |
| county Var | 0.108 | 0.041 |
# slope
#######################################################
res3.params["floor[T.ground]"]
-0.6929937406558051
# sigma-hat
np.sqrt(res3.scale)
0.7555891484188185
# standard deviation of the variability among county-specific Intercepts
np.sqrt(res3.cov_re)
| county | |
|---|---|
| county | 0.328222 |
# intercept deviation for first country in res3
res3.random_effects["LAC QUI PARLE"].values
array([0.40649212])
# compare with corresponding Bayesian point estimate
lqp = idata3.sel(county__factor_dim="LAC QUI PARLE")
post3_lqp_means = lqp["posterior"].mean()
post3_lqp_means["1|county"].values
array(0.41166284)
This is very close to the mean of the random effect coefficient for AITKIN in the Bayesian model mod3 which was \(-0.268\).
Random intercepts and slopes model using statsmodels (BONUS TOPIC)#
sm4 = smf.mixedlm("log_radon ~ 1 + floor", # Fixed effects (no intercept and floor as a fixed effect)
groups="county", # Grouping variable for random effects
re_formula="1 + floor", # Random effects: 1 for intercept, floor for slope
data=radon)
res4 = sm4.fit()
res4.summary().tables[1]
| Coef. | Std.Err. | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 1.463 | 0.054 | 26.977 | 0.000 | 1.356 | 1.569 |
| floor[T.ground] | -0.681 | 0.089 | -7.624 | 0.000 | -0.856 | -0.506 |
| county Var | 0.122 | 0.049 | ||||
| county x floor[T.ground] Cov | -0.040 | 0.057 | ||||
| floor[T.ground] Var | 0.118 | 0.120 |
# slope estimate
res4.params["floor[T.ground]"]
-0.6810977572101948
# sigma-hat
np.sqrt(res4.scale)
0.7461559982563551
# standard deviation of the variability among county-specific Intercepts
county_var_int = res4.cov_re.loc["county", "county"]
np.sqrt(county_var_int)
0.3486722110725758
# standard deviation of the variability among county-specific slopes
county_var_slopes = res4.cov_re.loc["floor[T.ground]", "floor[T.ground]"]
np.sqrt(county_var_slopes)
0.3435539748320226
# correlation between Intercept and slope group-level coefficients
county_floor_cov = res4.cov_re.loc["county", "floor[T.ground]"]
county_floor_cov / (np.sqrt(county_var_int)*np.sqrt(county_var_slopes))
-0.33723036077788177
Discussion#
Alternative notations for hierarchical models#
IMPORT FROM Gelman & Hill Section 12.5 printout
watch the subscripts!
Computational challenges associated with hierarchical models#
centred vs. noncentred representations
Benefits of multilevel models#
TODO LIST
Better than repeated measures ANOVA because:
tells you the direction and magnitude of effect
can handle more multiple grouping scenarios (e.g. by-item, and by-student)
works for categorical predictors
Applications#
Need for hierarchical models often occurs in social sciences (better than ANOVA)
Hierarchical models are often used for Bayesian meta-analysis
Exercises#
Exercise: mod1u#
Same model as Example 3 but also include the predictor log_uranium.
import bambi as bmb
covariate_priors = {
"floor": bmb.Prior("Normal", mu=0, sigma=10),
"log_uranium": bmb.Prior("Normal", mu=0, sigma=10),
"1|county": bmb.Prior("Normal", mu=0, sigma=bmb.Prior("Exponential", lam=1)),
"sigma": bmb.Prior("Exponential", lam=1),
}
mod1u = bmb.Model(formula="log_radon ~ 1 + floor + (1|county) + log_uranium",
priors=covariate_priors,
data=radon)
mod1u
Formula: log_radon ~ 1 + floor + (1|county) + log_uranium
Family: gaussian
Link: mu = identity
Observations: 919
Priors:
target = mu
Common-level effects
Intercept ~ Normal(mu: 1.2246, sigma: 2.1322)
floor ~ Normal(mu: 0.0, sigma: 10.0)
log_uranium ~ Normal(mu: 0.0, sigma: 10.0)
Group-level effects
1|county ~ Normal(mu: 0.0, sigma: Exponential(lam: 1.0))
Auxiliary parameters
sigma ~ Exponential(lam: 1.0)
Exercise: pigs dataset#
https://bambinos.github.io/bambi/notebooks/multi-level_regression.html
import statsmodels.api as sm
dietox = sm.datasets.get_rdataset("dietox", "geepack").data
dietox
| Pig | Evit | Cu | Litter | Start | Weight | Feed | Time | |
|---|---|---|---|---|---|---|---|---|
| 0 | 4601 | Evit000 | Cu000 | 1 | 26.5 | 26.50000 | NaN | 1 |
| 1 | 4601 | Evit000 | Cu000 | 1 | 26.5 | 27.59999 | 5.200005 | 2 |
| 2 | 4601 | Evit000 | Cu000 | 1 | 26.5 | 36.50000 | 17.600000 | 3 |
| 3 | 4601 | Evit000 | Cu000 | 1 | 26.5 | 40.29999 | 28.500000 | 4 |
| 4 | 4601 | Evit000 | Cu000 | 1 | 26.5 | 49.09998 | 45.200001 | 5 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 856 | 8442 | Evit000 | Cu175 | 24 | 25.7 | 73.19995 | 83.800003 | 8 |
| 857 | 8442 | Evit000 | Cu175 | 24 | 25.7 | 81.69995 | 99.800003 | 9 |
| 858 | 8442 | Evit000 | Cu175 | 24 | 25.7 | 90.29999 | 115.200001 | 10 |
| 859 | 8442 | Evit000 | Cu175 | 24 | 25.7 | 96.00000 | 133.200001 | 11 |
| 860 | 8442 | Evit000 | Cu175 | 24 | 25.7 | 103.50000 | 151.400002 | 12 |
861 rows × 8 columns
pigsmodel = bmb.Model("Weight ~ Time + (Time|Pig)", dietox)
pigsidata = pigsmodel.fit(random_seed=42)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [sigma, Intercept, Time, 1|Pig_sigma, 1|Pig_offset, Time|Pig_sigma, Time|Pig_offset]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 7 seconds.
We recommend running at least 4 chains for robust computation of convergence diagnostics
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
az.summary(pigsidata, var_names=["Intercept", "Time", "1|Pig_sigma", "Time|Pig_sigma", "sigma"])
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| Intercept | 15.748 | 0.565 | 14.712 | 16.812 | 0.033 | 0.016 | 290.0 | 621.0 | 1.00 |
| Time | 6.947 | 0.082 | 6.785 | 7.094 | 0.005 | 0.003 | 251.0 | 474.0 | 1.01 |
| 1|Pig_sigma | 4.549 | 0.443 | 3.739 | 5.399 | 0.018 | 0.011 | 599.0 | 883.0 | 1.00 |
| Time|Pig_sigma | 0.662 | 0.063 | 0.544 | 0.772 | 0.003 | 0.002 | 539.0 | 882.0 | 1.00 |
| sigma | 2.458 | 0.065 | 2.336 | 2.580 | 0.001 | 0.002 | 2437.0 | 1430.0 | 1.00 |
Exercise: educational data#
cf. https://mc-stan.org/users/documentation/case-studies/tutorial_rstanarm.html
1.1 Data example We will be analyzing the Gcsemv dataset (Rasbash et al. 2000) from the mlmRev package in R. The data include the General Certificate of Secondary Education (GCSE) exam scores of 1,905 students from 73 schools in England on a science subject. The Gcsemv dataset consists of the following 5 variables:
school: school identifier
student: student identifier
gender: gender of a student (M: Male, F: Female)
written: total score on written paper
course: total score on coursework paper
# import pyreadr
# path = "/Users/ivan/Desktop/stats stuff from desktop/Current Bayesian/Hierarchical models/mlmRev"
# Gcsemv_r = pyreadr.read_r(path + '/data/Gcsemv.rda')
# Gcsemv_r["Gcsemv"].dropna().to_csv("datasets/exercises/gcsemv.csv", index=False)
gcsemv = pd.read_csv("datasets/exercises/gcsemv.csv")
gcsemv.head()
| school | student | gender | written | course | |
|---|---|---|---|---|---|
| 0 | 20920 | 27 | F | 39.0 | 76.8 |
| 1 | 20920 | 31 | F | 36.0 | 87.9 |
| 2 | 20920 | 42 | M | 16.0 | 44.4 |
| 3 | 20920 | 101 | F | 49.0 | 89.8 |
| 4 | 20920 | 113 | M | 25.0 | 17.5 |
import bambi as bmb
m1 = bmb.Model(formula="course ~ 1 + (1 | school)", data=gcsemv)
m1
Formula: course ~ 1 + (1 | school)
Family: gaussian
Link: mu = identity
Observations: 1523
Priors:
target = mu
Common-level effects
Intercept ~ Normal(mu: 73.3814, sigma: 41.0781)
Group-level effects
1|school ~ Normal(mu: 0.0, sigma: HalfNormal(sigma: 41.0781))
Auxiliary parameters
sigma ~ HalfStudentT(nu: 4.0, sigma: 16.4312)
idata_m1 = m1.fit(random_seed=42)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [sigma, Intercept, 1|school_sigma, 1|school_offset]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 3 seconds.
We recommend running at least 4 chains for robust computation of convergence diagnostics
az.summary(idata_m1)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| sigma | 13.977 | 0.261 | 13.509 | 14.491 | 0.006 | 0.007 | 2048.0 | 1321.0 | 1.01 |
| Intercept | 73.840 | 1.115 | 71.988 | 76.025 | 0.049 | 0.028 | 519.0 | 1064.0 | 1.00 |
| 1|school_sigma | 8.815 | 0.927 | 7.096 | 10.525 | 0.040 | 0.024 | 532.0 | 738.0 | 1.01 |
| 1|school[20920] | -6.778 | 4.959 | -15.831 | 2.183 | 0.097 | 0.108 | 2595.0 | 1502.0 | 1.00 |
| 1|school[22520] | -15.663 | 2.153 | -19.718 | -11.557 | 0.059 | 0.044 | 1319.0 | 1208.0 | 1.00 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1|school[76531] | -11.258 | 5.320 | -21.564 | -1.933 | 0.105 | 0.128 | 2587.0 | 1265.0 | 1.00 |
| 1|school[76631] | 2.099 | 2.700 | -2.607 | 7.672 | 0.059 | 0.053 | 2076.0 | 1637.0 | 1.00 |
| 1|school[77207] | -3.106 | 3.427 | -9.332 | 3.241 | 0.071 | 0.077 | 2339.0 | 1532.0 | 1.00 |
| 1|school[84707] | 4.133 | 7.504 | -10.680 | 17.411 | 0.154 | 0.189 | 2406.0 | 1230.0 | 1.00 |
| 1|school[84772] | 8.542 | 3.652 | 1.880 | 15.254 | 0.076 | 0.079 | 2306.0 | 1554.0 | 1.00 |
76 rows × 9 columns
m3 = bmb.Model(formula="course ~ gender + (1 + gender|school)", data=gcsemv)
m3
Formula: course ~ gender + (1 + gender|school)
Family: gaussian
Link: mu = identity
Observations: 1523
Priors:
target = mu
Common-level effects
Intercept ~ Normal(mu: 73.3814, sigma: 53.4663)
gender ~ Normal(mu: 0.0, sigma: 83.5292)
Group-level effects
1|school ~ Normal(mu: 0.0, sigma: HalfNormal(sigma: 53.4663))
gender|school ~ Normal(mu: 0.0, sigma: HalfNormal(sigma: 83.5292))
Auxiliary parameters
sigma ~ HalfStudentT(nu: 4.0, sigma: 16.4312)
idata_m3 = m3.fit(random_seed=42)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [sigma, Intercept, gender, 1|school_sigma, 1|school_offset, gender|school_sigma, gender|school_offset]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 6 seconds.
We recommend running at least 4 chains for robust computation of convergence diagnostics
Exercise: sleepstudy dataset#
Description: Contains reaction times of subjects under sleep deprivation conditions.
Source: Featured in the R package lme4.
Application: Demonstrates linear mixed-effects modeling with random slopes and intercepts.
Links:
sleepstudy = bmb.load_data("sleepstudy")
sleepstudy
| Reaction | Days | Subject | |
|---|---|---|---|
| 0 | 249.5600 | 0 | 308 |
| 1 | 258.7047 | 1 | 308 |
| 2 | 250.8006 | 2 | 308 |
| 3 | 321.4398 | 3 | 308 |
| 4 | 356.8519 | 4 | 308 |
| ... | ... | ... | ... |
| 175 | 329.6076 | 5 | 372 |
| 176 | 334.4818 | 6 | 372 |
| 177 | 343.2199 | 7 | 372 |
| 178 | 369.1417 | 8 | 372 |
| 179 | 364.1236 | 9 | 372 |
180 rows × 3 columns
Exercise: tadpoles (BONUS)#
https://www.youtube.com/watch?v=iwVqiiXYeC4
logistic regression model